
MongoDB vs MySQL: A Comparative Study on Databases
Introduction
Building a database isn’t easy at it sounds. Browse through our comparative study on databases: MongoDB vs MySQL. Understand the differences and analyze based on parameters such as performance, schema flexibility, relationships, security, etc. Explore through use cases and pros & cons.
Maybe your organization settled on the perfect database model and you thought that it will be static for years, if not decades.
But your predictions didn’t go right!
Just like the 99.999% of world organizations, your business is in continuous flux and you’ve been doing better than expected (I’m happy for you! 🙂 ) but the time has come when it is demanding constant iterations in the way you do your business. Trust me, no company has developed great software without iterations.
And the key to confronting these challenges of today’s business is the foundation of strong and flexible data infrastructure.
Imagine finding a DBMS which aligns with tech goals of your organization! Pretty exciting, right?
Relational databases held the lead for quite a time. Choices were quite obvious, MySQL, Oracle or MS SQL to mention a few.
Though times have changed pretty much with the demand for more diversity and scalability, isn’t it?
There are many alternatives in the market to choose from; though I don’t want you to get all confused again, and hence, what about a faceoff between two dominant solutions that are cut-throat in popularity?
MongoDB vs MySQL?
This isn’t a half-baked idea, sure! You’ll love it.
There is no cost here!
Since, both the database are free and open-source database software, all I need here is your reading time.
On that note, let’s get started.
-
What is MongoDB?
-
What is MySQL?
-
MongoDB vs MySQL: Comparison Chart
-
When to use MongoDB?
-
MongoDB: Pros & Cons
-
MongoDB Use Cases
-
When to use MySQL
-
MySQL: Pros & Cons
-
MySQL Use Cases
What is MongoDB
MongoDB is one of the most popular document-oriented databases under the banner of NoSQL database. It was developed from an idea in 2007 and its first version was released in 2010. It is developed and maintained by MongoDB Inc.
It employs the format of key-value pairs, here called document store. Document stores in MongoDB are created is stored in BSON files which are, in fact, a little-modified version of JSON files and hence all JS are supported.
Because of this, it is frequently used for Node.js projects. Moreover, JSON facilitates the exchange of data between web apps and servers in a human-readable format.
Not only that, it offers greater efficiency and reliability which in turn can meet your storage capacity and speed demands.
On top of it, the schema-free implementation of MongoDB eliminates the prerequisites of defining a fixed structure. These models allow hierarchical relationships representation and facilitate the ability to change the structure of the record.
Also, this NoSQL solution is added to the benefits of auto-sharding, embedding and on-board replication which in turn provides high scalability and availability.
What is MySQL?
MySQL is an open-source relational database management system RDBMS. It was originally built by MySQL AB though presently owned by Oracle.
It employs the concept of storing data in rows and tables which are further classified into the database. It uses Structured Query Language SQL to access and transfer the data and commands such as “SELECT’, ‘UPDATE’, ‘INSERT’ and ‘DELETE’ to manage it.
Related information is stored in different tables but the concept of JOIN operations simplifies the process of correlating it and performing queries across multiple tables and minimize the chances of data duplication.
Though, MySQL’s limitations are the same as of relational databases. Millions of read/write highly affects the performance and hence horizontal scaling is not quite easy.
Although replication and clustering are available still it cannot ease the pain to implement or compensate for the basic relational database design problems.
Serverless Architecture Guide
Serverless Use Cases
Custom Software
MongoDB vs MySQL: Comparison Chart
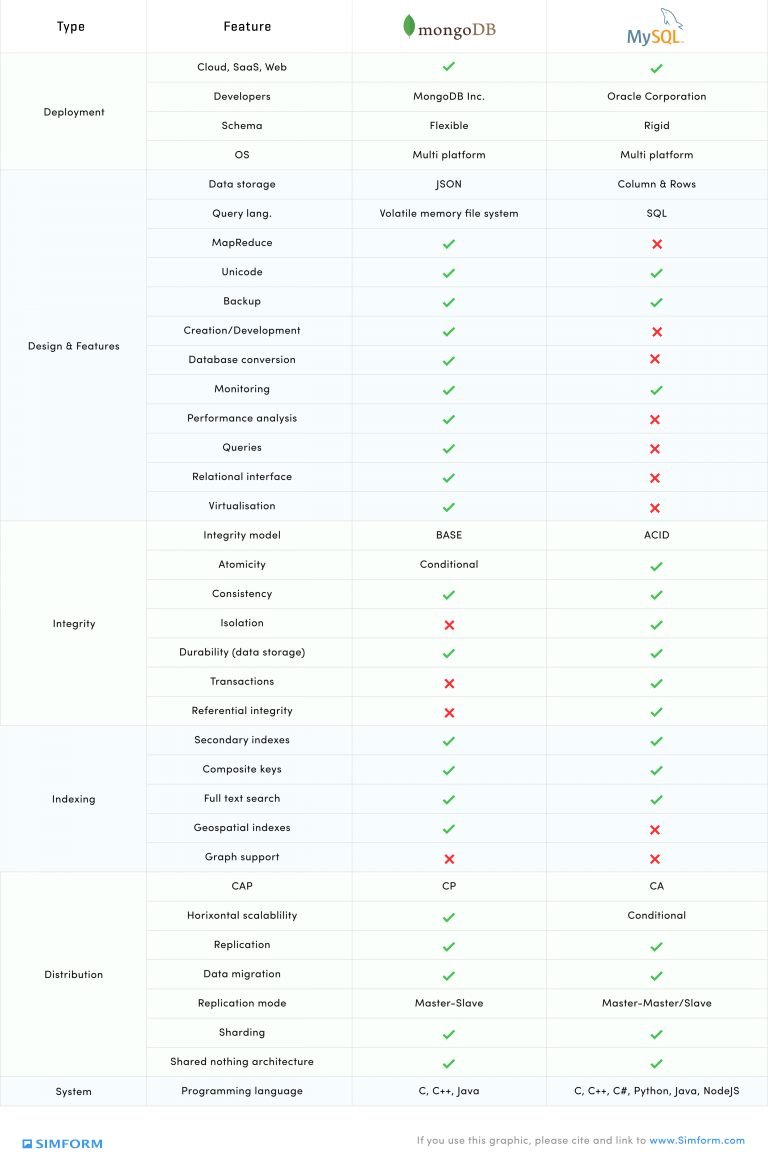
Deployment & Community Support
MongoDB: It is currently owned and developed by MongoDB Inc. It is extremely easy to deploy MongoDB. It is also available for SaaS, Cloud and Web applications and can run on multiple platforms including Linux, Windows and MacOS.
MongoDB has been observed to attract users with its clean and simple philosophy apart from its collaborative and helping community.
MySQL: It is currently owned and developed by Oracle Corporation. MySQL can be installed manually from the source code itself.
It is available for SaaS, Cloud and Web applications and can run on multiple platforms including Linux, Windows and MacOS. One advantage of MySQL is that it has been around the block for a good time and hence it has a strong community.
Flexibility of Schema: MongoDB vs MySQL
MongoDB: One of the best things about MongoDB is that there are no restrictions on schema design. You can just drop a couple of documents within a collection and it isn’t necessary to have any relation to those documents. The only restriction with this is supported data structures.
Though, due to the absence of joins and transactions (which we will discuss later), you need to frequently optimize your schema based on how the application will be accessing the data.
MySQL: Before you can store anything in MySQL, you need to clearly define tables and columns and also, every row in the table should have the same column.
And because of this, there isn’t much space for flexibility in the manner of storing data if you follow normalization. Development and deployment process is slowed down as well due to the fact that even a little modification in data model mandates the change in schema design.
For example, if you run a bank, its information can be added to the table named ‘account’ as follows:
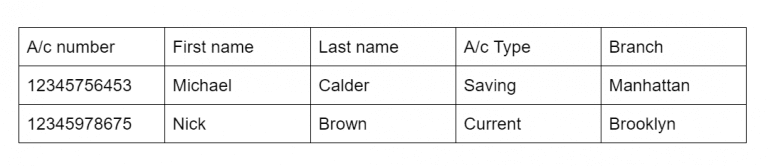
This is how MySQL stores the data. As you can see, the table design is quite rigid and it is not easily changeable. You can’t even type letters where numbers are expected.
MongoDB stores the data in the JSON type manner as described below:

Such documents can be stored in a collection as well.

MongoDB creates schemaless documents which can store any information you want though it may cause problems with data consistency. MySQL creates a strict schema-template and hence it is bound to make mistakes.
Querying Language in MongoDB & MySQL
MongoDB: This uses un-Structured Query Language. To build a query in JSON documents, you need to specify a document with properties you wish the results to match.
It is typically executed using a very rich set of operators, linked with each other using JSON. MongoDB treats each property as having an implicit boolean AND. It natively supports boolean OR queries, but you must use a special operator ($or) to achieve it.
MySQL: This uses the Structured Query Language SQL to communicate with the database. Despite its simplicity, it is indeed a very powerful language which consists mainly of two parts: Data Definition Language DDL & Data Manipulation Language DML.
As discussed earlier, you can use the following commands to query the data in MySQL database- ‘SELECT’, ‘UPDATE’, ‘INSERT’ and ‘DELETE’.
Let’s have a quick comparison.
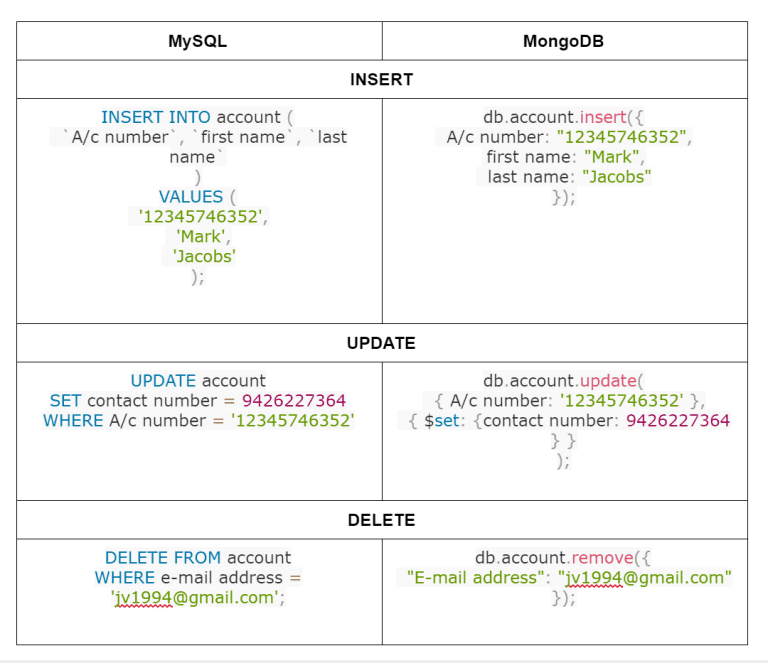
Relationships in MongoDB & MySQL
MongoDB: This doesn’t support JOIN directly, rather it has JOIN equivalent- $lookup operator. This can be included as one of the stages in the aggregated pipeline. With the help of this operator, the work of combining data into a single query from multiple documents is possible. And hence, there is lesser work to code with quality in the application.
For example, you want a list of people with the savings account, where the ‘id’ field of multiple documents from the ‘Account’ collection is included in a document from the ‘Savings account list’ collection. For a query to analyze ‘savings account list’ and their associated ‘accounts’, it must fetch the ‘saving account list’ document and then use the embedded references to read multiple documents from the accounts collection.

MySQL: One of the best parts about MySQL is the JOIN operations. To put it in simple terms, JOIN makes the relational database ‘relational’. JOIN allows the user to link data from two or more tables in a single query with the help of single ‘SELECT’ command.
For example, we can easily obtain related data in multiple tables using a single SQL statement.

This should provide you with A/c number, first name and respective branch.
Integrity Model- ACID and BASE
MongoDB: This follows the BASE (Basic Availability, Soft-state and Eventual consistency) model.
It supports atomic updates on a single document level. Though it is possible to execute transaction like semantic over MongoDB but it will demand quite complex implementations.
What are atomic transactions?
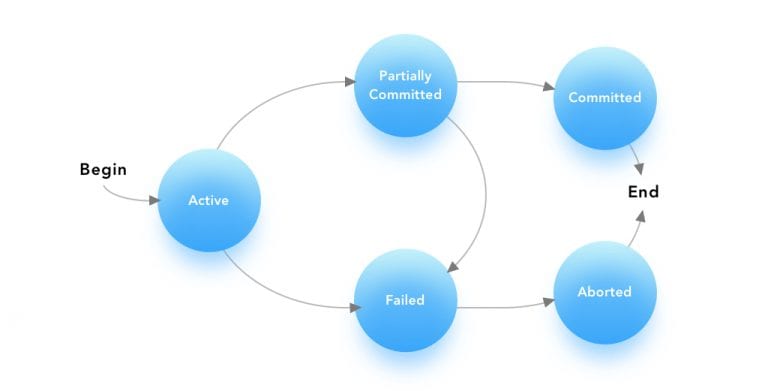
With all or nothing that assures success or failure of a transaction, two or more updates can be executed in a MongoDB database.
For example, presume our account table contained deposit and A/C balance tables.
When some money is deposited in the account, we add that sum to the account balance. If we execute those two updates individually, one could succeed and the other fail- thus leaving figures out of sync.
Placing the same up
MongoDB supports atomic modifications. In other words, if you’re updating two values within a document, either all two are updated successfully or remains unchanged.
It didn’t support transactions or guarantee data consistency till now. But updates in MongoDB 3.6 such as the introduction of client sessions and casual consistency has led to the provision of more flexibility to the application developer to fine tune the desirable consistency the app requires.
MongoDB provides tunable consistency model through the readConcern and writeConcern parameters. A causally consistent session denotes that the associated sequence of read and acknowledged write operations have a causal relationship that is reflected by their ordering. Applications must ensure that only one thread at a time executes these operations in a client session. We have used MongoDB for one of our clients to enhance the scalability of read-write operations. Here’s the full case study.
MySQL: This follows the ACID (Atomic, Consistent, Isolated and Durable) model. This means that once a transaction is complete, the data remains consistent and stable on the disc which may include distinct multiple memory locations.
This is quite suitable for applications which can’t bear data loss or inconsistency. However, transactions are known for limiting horizontal scalability.
Availability of Full-text Search
MongoDB: Full-text search wasn’t supported by MongoDB until recently. Likewise MySQL, it is executed using a specific type of index on the array of strings. Moreover, it also supports the phrase search and terms search.
Boolean search is supported as a combination of terms search and phrase search. It is an easily executable feature though it has some limitations as well.
At present, it isn’t facilitating any control over specifying the fields of subsets to perform a full-text search. It consistently matches all the included field in the full-text search.
MySQL: This supports full-text searching for a long time which is executed with the help of a special type of index. It is facilitated using natural language search (phrase search), boolean search (terms search) and query search.
However, at present, full-text indexing is not supported in clustered MySQL databases.
CAP Theorem: Consistency, Availability & Partition
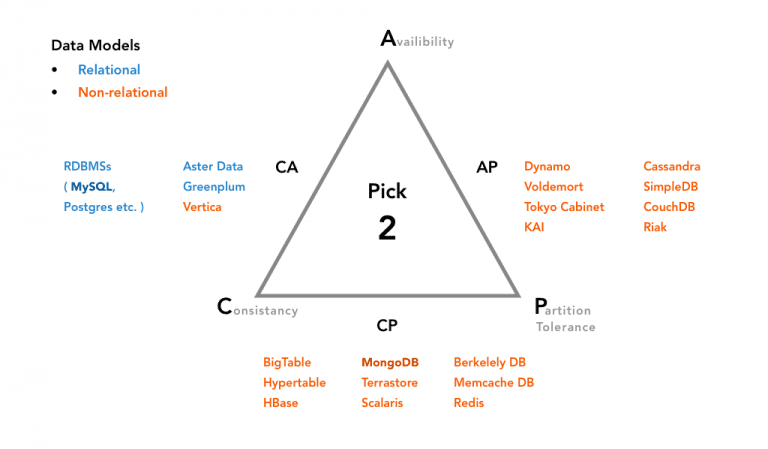
MongoDB: MongoDB database under the CAP theorem opts for Consistency & Partition tolerance (i.e. CP). What does this mean? This means that the consistent view of the database will be available for all the clients to see.
Though the users of one node will have to wait for any other nodes to come to an agreement before being able to read or write to the database. In this case, the availability takes a backseat to consistency.
MySQL: MySQL database under the CAP theorem opts for Consistency & Availability (i.e. CA). What does this mean? This means that data will be consistent between all nodes as long as nodes are online.
This will also allow you to read/write from any node and be sure that the data is consistent. If ever a partition between node is developed, the data will be out of sync and won’t resolve until the partition is resolved.
Sharding: MongoDB vs MySQL
Sharding is the method of distributing data across multiple machines to support deployments with large data sets and high throughput operations.
High query rates and datasets larger than system RAM can put stress on I/O capacity of disk drives and CPU of the server. These problems are solved by horizontal and vertical scaling.
-
Vertical scaling involves increasing the capacity of a single server by adding more RAM, powerful CPU, or storage space.
-
Horizontal scaling includes dividing the dataset and load over multiple additional servers. Each machine handles a part of the workload with a comparatively lower cost than high-end hardware for a single machine.
MongoDB: Its sharding has the ability to break up a collection into subsets of data to store them across multiple shards. This allows the application to grow beyond the resource limits of a standalone server or replica set.
Also, it can handle the distribution of data across any number of nodes to maximize the use of disc space and dynamically load balance queries. It also empowers users with automated failure and redundancy.
Like MySQL, MongoDB sharding has the ability to perform range-based data partitioning. MongoDB also supports automatic data volume distribution and transparent query routing.
A MongoDB sharded cluster consists of shard, mongos (query router) and config servers (store metadata and configuration settings).
Mongo is very good in some areas where relational databases are particularly weak, like application-unaware scaling, auto-sharding, and maintaining flat response times even as dataset size balloons.
While sharding in MongoDB is standardized, database architects should keep in mind the following considerations:-
-
Cardinality – Choose a shard key which is easy to split later if the database size is exceeding chunk size.
-
Distribution – Sharding key should spread in a uniform distribution to avoid unbalanced design.
-
Query – Each of your queries will result in a single shard key if any of the queries have the shard key. Otherwise, it will generate queries for each shard.
MySQL: At some point in time, you need to scale your MySQL database. And you will opt for replication. Though, it is quite easy to add read scale to MySQL but what about write scale?
Here comes the difficult part! Multi-master replication can add additional write scale but only for separate applications, each application must write to different master to get that scale.
Unlike MongoDB, MySQL there is no standard sharding implementation. Though MySQL offers two ways for the sharding ie. MySQL Cluster – built-in Automatic sharding functionality and MySQL Fabric – official sharding framework, they are rarely deployed. The common practice is to roll your own sharding framework as Facebook and Pinterest have done.
Database administrators need to take the design decision on the choice of sharding key, schema changes and mapping between sharing the key, shards and physical servers.
The wrong choice in sharding key will lead to system inflexibility. For example, parent/child relationship between tables won’t be automatically maintained if the parent and child rows are in separate databases.
Thus the use of intelligent sharding keys or hashed sharding keys is critical. Also, sharding key changes can have a knock-on effect on application, data location, and transactionality across nodes.
Data inconsistency can creep in if shards have not completed their schema changes. Also, schema changes require coordination across multiple separate MySQL instances which exposes the application to potential errors and downtime.
Creating and maintaining the mapping between sharding keys, data partitions, databases and nodes is very essential. The changes in mapping due to shard splits, shard migrations, instance replacement, and sharing key changes should be done in a very fast lookup.
Replication
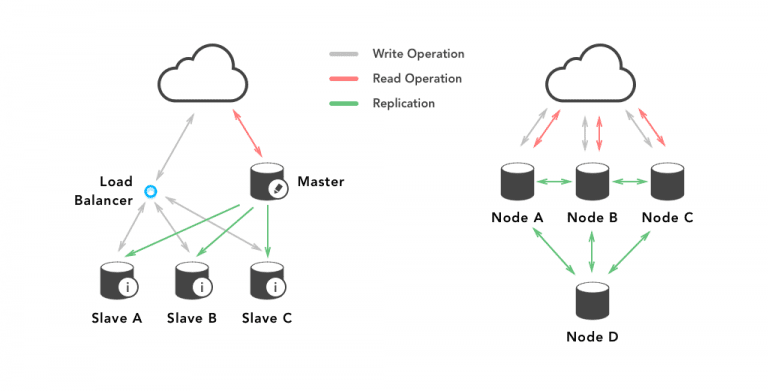
MongoDB: This supports only master-slave replication. It uses replica sets to create multiple copies of the data. Each member of the replica set will be assigned primary or secondary role at any point in the process.
By default, read/writes are done on primary replica and then replicated on the secondary replicas.
MySQL: This supports both master-slave replication and master-master replication. Multi-source replication gives you the ability to replicate data from several masters in parallel. In master-slave replication, consistency is not too difficult as each piece of data has exactly one owing master.
While in master-master replication, if you can make it work, they seem to offer everything you want with no single point of failure.
MongoDB vs MySQL: Performance & Speed
MongoDB: One single main benefit it has over MySQL is its ability to handle large unstructured data. It is magically faster. People are experiencing real world MongoDB performance mainly because it allows users to query in a different manner that is more sensitive to workload.
MySQL: Developers note that MySQL is quite slow in comparison to MongoDB when it comes to dealing with the large database. Hence, it is a better choice for users with small data volume and is looking for a more general solution as it is unable to cope with large and unstructured amounts of data.
As such, there is no “standard” benchmark that can help you with the best database to use for your needs. Only your demands, your data and infrastructure can tell you what you need to know.
Let’s take a general example to understand the speed of MySQL and MongoDB in accordance with various functions.
Measurements have been performed in the following cases:
-
MySQL 5.7.9
-
MongoDB 3.2.0
Each of these has been tested on a separate m4.xlarge Amazon instance with the ubuntu 14.4 x64 and default configurations, all tests were performed for 1000000 records.
MySQL vs MongoDB: ‘SELECT’, ‘UPDATE’ & ‘INSERT’ Performance
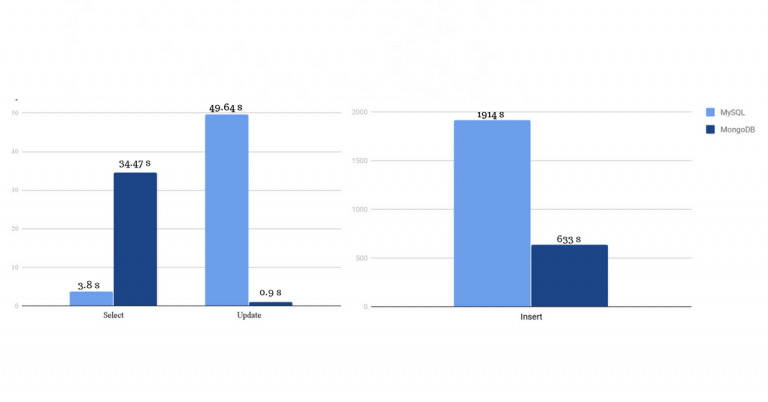
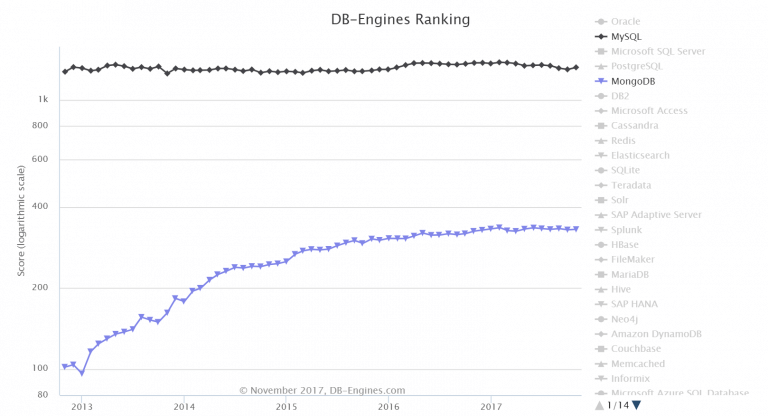
It is evident from the above graph that MongoDB takes way more lesser time than MySQL for the same commands. And this must have answered your question: how fast is MongoDB compared to MySQL!
Security Model for MongoDB vs MySQL
MongoDB: This uses a role-based access control with a flexible set of privileges. Its security features include authentication, auditing and authorization.
Moreover, it is also possible to use Transport Layer Security TLS and Secure Sockets Layer SSL for encryption purposes. This ensures that it is only accessible and readable by the intended client.
MySQL: This uses a privilege based security model. This means it authenticates a user and facilitates it with user privileges on a particular database such as CREATE, SELECT, INSERT, UPDATE and so on.
Though, it fails to explain why a given user is denied specific access. On the transport layer, it uses encrypted connections between clients and the server using the SSL.
When to use MongoDB?
If the following are your requirements, you should be using MongoDB:
-
When you need high availability of data with automatic, fast and instant data recovery.
-
In future, if you’re going to grow big as MongoDB has in-built sharding solution.
-
If you have an unstable schema and you want to reduce your schema migration cost.
-
If you don’t have a Database Administrator (but you’ll have to hire one if you’re going to go BIG).
-
If most of your services are cloud-based, MongoDB is best suitable for you, as its native scale-out architecture enabled by ‘sharding’ aligns well with horizontal scaling and agility offered by cloud computing.
MongoDB: Pros & Cons
-
MongoDB is best when you want the flexibility of schema. You can easily use replica sets with MongoDB and can take advantage of scalability. Expansion plans are flexible and can be easily achieved by adding more machines and RAM to the system. It also includes document validations and integrated systems.
-
The cons of MongoDB include higher data size over the period of time. Due to the lack of atomic transactions, the speed is comparatively low compared to NoSQL. Also, the solution is quite infant and hence cannot replace the legacy systems directly.
MongoDB Use Cases
Cisco e-commerce
Before migrating to MongoDB, Cisco’s e-commerce platform that was responsible to cater to 150,000+ user faced the following challenges:
-
Fault tolerance and resilience
-
Zero downtime on new code deployments
-
Poor page response time
Cisco now benefits from MongoDB, their pre-deployment testing results showed:
-
When applied 5 times the normal peak load, the throughput and latency remained the same.
-
MongoDB was able to self-heal within 2 seconds upon being introduced to a range of failure conditions.
-
High resilience with MongoDB’s architecture, without any interruptions.
Craigslist
Craigslist was posting more than 1.5 million ads each day, storing its data in a MySQL Cluster. But this setup lacked flexibility and management costs became unsustainable.
The migration of Craigslist to MongoDB benefit them as:
-
It reduced costly schema migrations.
-
Auto-Sharding and high availability reduced operational pains.
Horizontal scalability didn’t require custom, complex sharding code.
MTV Networks
MTV was initially using a Java-based content management platform, this platform was backed by an ill-suited data model. Adding new data types and tables significantly reduce read performance.
They decided to move towards MongoDB to grow, scale and represent data as they wanted to bring more brands onto their existing platform. This database migration helped them:
-
Store hierarchical data
-
Efficiently query nested content
-
To scale with database clustering
When to use MySQL?
If the following are your requirements, you should be using MySQL:
-
If you’re just starting and your database is not going to scale much, MySQL will help you in easy and low-maintenance setup.
-
If you’ve fixed schema and a data structure aren’t going to change over the time like Wikipedia.
-
If you want high performance on a limited budget.
-
If high transaction rate is going to be your requirement (like BBC around 30,000 inserts/minute, 4000 selects/hour)
-
If data security is your top priority, MySQL is the most secure DBMS.
MySQL: Pros & Cons
-
MySQL is around the block for a long time. One of the main pros is that it’s community driven. Being a mature solution, it supports JOIN, atomic transactions with privilege and password security system.
-
With MySQL, you may end devoting a lot of time and efforts which other platforms might do automatically for you, like incremental backups. The main issue with MySQL is scalability. No inbuilt XML and OLAP.
MySQL Use Cases
Wikipedia
Wikipedia’s growth statistics are simply amazing. These include:
-
Monthly visitor growth from less than 50,000 to over 350 million
-
Content growth from less than 100 articles to over 15 million
-
Contributor growth from less than 100 to over 300,000
Wikipedia expects the growth in all directions – and needs a computing infrastructure that will keep the pace. This phenomenal growth has put constant technical pressure on the performance and scalability of the system.
Their scale-out solution came in the following ways:
-
Scaling from single shard server to top 10 sites on the internet
-
More than 20 replicated servers serving up-to-date content to visitors.
-
Accommodation of more visitors and content as per the rising demand
-
Enabling half a million edits and thousands of entries.
Plus, saving on hardware costs since they add new servers only on an incremental, as-needed basis, they can delay their new hardware purchases until more powerful machines drop to lower, commodity prices.
BBC
35 million unique users and receives over 800 million page impressions each month.
The BBC wanted to work in real-time with a dynamic system which would give audiences a real sense of the news stories on the website being selected most by other users.
Though, the challenge was to balance a demand for high performance with value for money on a limited budget.
MySQL helped them in building an in-house system where it was possible to monitor the number of stories read hour by hour during the day as well as which story and video have been the top during each hour of the day so far.
Technical specs about the above-mentioned system:
-
Number of tables in MySQL database: 24, excluding merge tables
-
Number of records in the Largest Table: up to 4 million
-
Size of database: around 8 million rows
-
Number of transactions: around 30,000 inserts/minute, 4000 selects/hour.
-
MySQL server version 5.08 is currently used. The MyISAM merge tables function proved to speed up performance significantly. Development work and performance have been good.
Here’s the story of a transition from Twitter’s old way of storing tweets using temporal sharding, to a more distributed approach using a new tweet store called T-bird, which is built on top of Gizzard, which is built using MySQL.
-
Temporally sharded tweets was a good-idea-at-the-time architecture. Temporal sharding simply means tweets from the same date range are stored together on the same shard.
-
The problem is tweets filled up one machine, then a second, and then a third. You end up filling up one machine after another.
-
This is a pretty common approach and one that has some real flaws:
#1. Load balancing: Most of the old machines didn’t get any traffic because people are interested in what is happening now, especially with Twitter.
#2. Expensive: They filled up one machine, with all its replication slaves, every three weeks, which is an expensive setup.
#3. Logistically complicated: Building a whole new cluster every three weeks is a pain for the DBA team.
Gizzard implements a tweet store that isn’t perfect in the sense of load balancing, but it allows:
-
Growing slowly over time without having to worry when machines are going to fill up or when they have to make a hard cut over at an exact time.
-
DBAs can get some sleep. They don’t have to make those decisions as frequently and they don’t have to scale as inefficiently cost wise.
Conclusion
To answer the main question on “Why I should use X over Y?” you need to take into consideration your project goals and many other relevant things.
MySQL is highly-organized for its flexibility, high performance, reliable data protection and ease in management of data. Proper data indexing can resolve your issue with performance, facilitate interaction and ensure robustness.
But if your data is not structured and complex to handle, or pre-defining your schema is not coming off easy for you, you should better opt for MongoDB. What’s more, if it is required to handle a large volume of data and store it as documents- MongoDB will help you a lot!
The result of the faceoff- one isn’t necessarily a replacement for the other one. MongoDB & MySQL both serve in a different niche. For example, we have used both SQL and NoSQL databases for our client’s project called Freewire. Here’s the case study.
Though, what I am sure about is that the older solution wasn’t as suitable for a specific need, thus the invention of the new solution to fill that void.