Data Governance Framework Summary
Regards to Deniel Vitaver, who is the best professor I’ve experienced in my AI program at GBC. The only pity is that it lasted only 20 days, but the professor tried his best to keep us learning.
Data Management
Business Drivers
- enable organizations to get value from their datasets
Principles
- Data is an asset with unique properties
- Data value should be expressed in economic terms
- Managing data means managing the quality of data
- It takes metadata to manage data
- It takes planning to manage data (architecture, processes, etc.)
- Data management is cross-functional, requires skills, expertise and leadership vision, commitment, purpose
- Data management requires an enterprise perspective and requires data governance program to be effective
- Data management is lifecycle management
- Different types of data have different lifecycle characteristics
- Data management includes risk associated with data
- Data management requirements must drive IT decisions – Data is dynamic, it constantly evolves
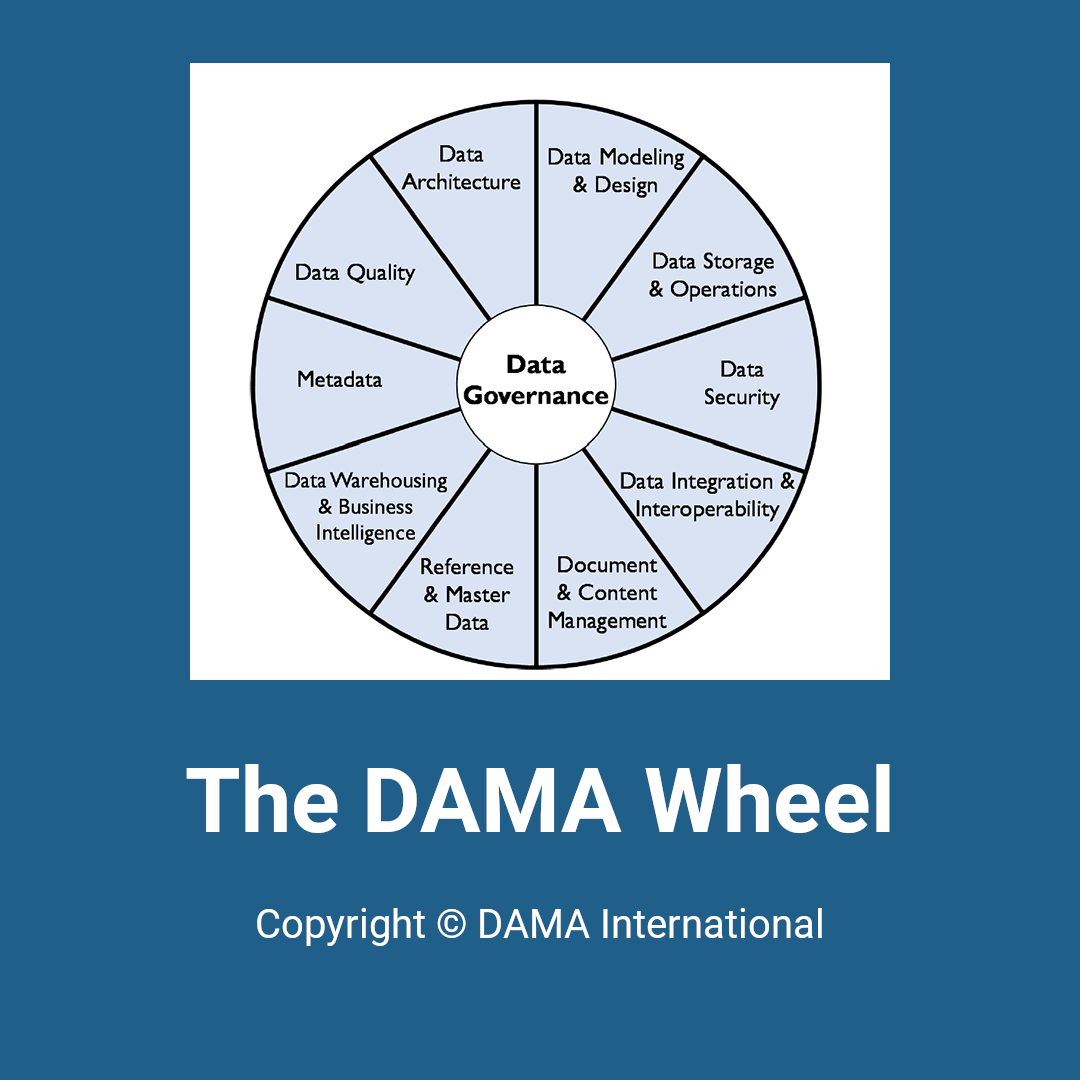
DAMA Wheel
- Data Governance
- Metadata
- Data Quality
- Data Architecture
- Data Modelling & Design
- Data Storage & Operations
- Data Security
- Data Integration & Interoperability
- Document & Content Management
- Reference & Master Data
- Data Warehouse & Business Intelligence
Data Governance
Data Governance is a system of rights and accountabilities, and the enforcement of authority over the management of all data and data-related assets of the organization.
Business Drivers
- reduce risk
- improve processes
Data policies are directives that codify principles and management intent into fundamental rules governing the creation, acquisition, integrity, security, quality, and use of data and information.
- Data Architecture: Enterprise data models, tool standards, and system naming conventions
- Data Modelling & Design: Data model management procedures, data modelling naming conventions, definition standards, standard domains, and standard abbreviations.
- Data Storage and Operations: Tool standards, standards for database recovery and business continuity, database performance, data retention, and external data acquisition.
- Data Security: Data access security standards, monitoring and audit procedures, storage security standards, and training requirements
- Data integration and Interoperability: Standard methods and tools used for data integration and interoperability.
- Documents and Content: Content management standards and procedures, including use of enterprise taxonomies, support for legal discovery, document and email retention periods, electronic signatures, and report distribution approaches.
- Reference and Master Data: Reference Data Management control procedures, systems of data records, assertions establishing and mandating use, standards for entity resolution.
- Data Warehousing and Business Intelligence: Tool standard, processing standards and procedures, report and visualization formatting standards, standards for Big Data handling.
- Metadata: Standard business and technical Metadata to be captured, Metadata integration procedures and usage
- Data Quality: Data quality rules, standard measurement methodologies, data remediation standards and procedures
- Big Data and Data Science: Data source Identification authority, acquisition, system of record, sharing and refresh.
Strategic Alignment
- Accountability: roles and responsibilities in the defined organizational chart
- Data Inventory: data stewards to maintain the inventory of all data using metadata tools
- Business Processes: establish processes for managing data in massive storage and data analysis tools
- Policies, Procedures and Rules: define data protection, classification, compliance and security
Principles
- Leadership and Strategy: Successful Data Governance starts with visionary and committed leadership. Data management activities are guided by a data strategy that is itself driven by the enterprise business strategy.
- Business-driven: Data Governance is a business program, and, as such, must govern IT decisions related to data as much as it governs business interaction with data.
- Shared responsibility: Across all Data Management Knowledge Areas, data governance is a shared responsibility between business data stewards and technical data management professionals.
- Multi-layered: Data governance occurs at both the enterprise and local levels and often at levels in between.
- Framework-based: because data governance activities require coordination across functional areas, the DG program must establish an operating framework that defines accountabilities and interactions.
- Principle-based: Guiding principles are the foundation of DG activities, and especially of DG policy. Often, organizations develop policy without formal principles - they are trying to solve particular problems. Principles can sometimes be reverse-engineered from policy. However, it is best to articulate a core set of principles and best practices as part of policy work. Reference to principles can mitigate potential resistance. Additional guiding principles will emerge over time within an organization. Publish them in a shared internal environment along with other data governance artifacts.
Metrics
- Value
- Effectiveness
- Sustainability
Metadata Management
Business Drivers
- increase confidence in data by providing context and enabling the measurement of data quality
- increase the value of strategic information by enabling multiple uses
- improve operational efficiency by identifying redundant data and processes
- prevent the use of out-of-date or incorrect data
- reduce data-oriented research time
- improve communication between data consumers and IT professionals
- create accurate impact analysis thus reduce the risk of project failure
- improve time-to-market by reducing system development life-cycle time
- reduce training cost and lower the impact turnover through thorough documentation of data context, history, and origin
- support regulatory compliance
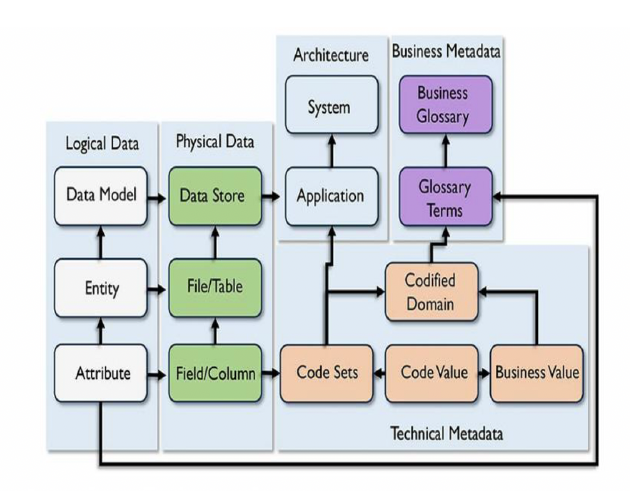
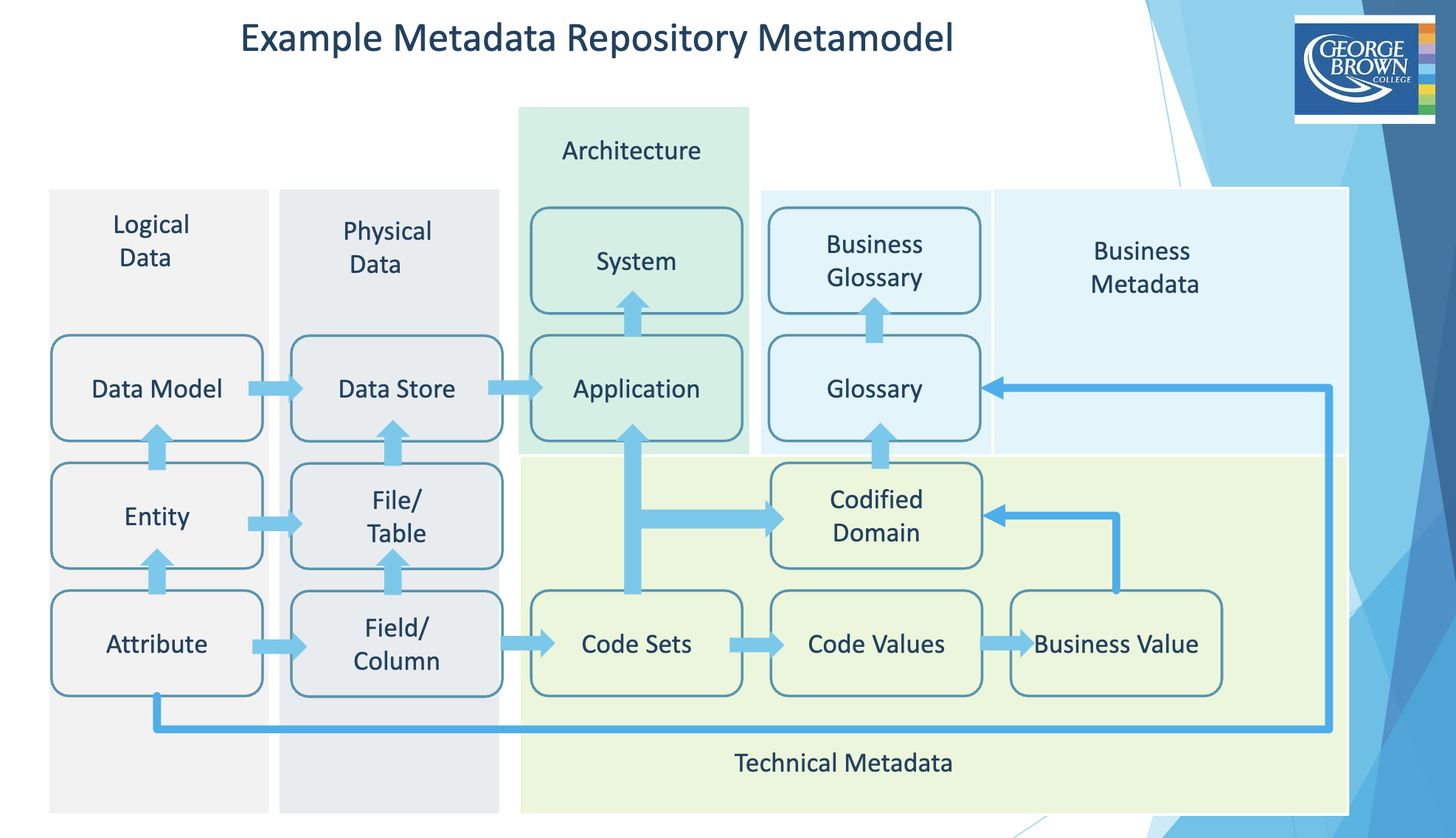
Metadata includes information about technical and business processes, data rules and constraints, and logical and physical data structures. It describes the data itself(e.g., databases, data elements, data models), the concepts the data represents (e.g., business processes, application systems, software code, technology infrastructure), and the connections (relationships) between the data and concepts. Metadata helps an organization understand its data, its systems, and its workflows.
A Metadata Repository refers to the physical tables in which the Metadata is stored.
Types
- Business Metadata
- Technical Metadata
- Operational Metadata
Principles
- Organizational commitment Secure organizational commitment (senior management support and funding) to Metadata management as part of an overall strategy to manage data as an enterprise asset.
- Strategy: Develop a Metadata strategy that accounts for how Metadata will be created, maintained, integrated, and accessed. The strategy should drive requirements, which should be defined before evaluating, purchasing, and installing Metadata management products. The Metadata strategy must align with business priorities.
- Enterprise perspective: Take an enterprise perspective to ensure future extensibility, but implement through iterative and incremental delivery to bring value.
- Socialization: Communicate the necessity of Metadata and the purpose of each type of Metadata; socialization of the value of Metadata will encourage business use and, as importantly, the contribution of business expertise.
- Access: Ensure staff members know how to access and use Metadata.
- Quality | Accountability: Recognize that Metadata is often produced through existing processes (data modelling, SDLC, business process definition) and hold process owners accountable for the quality of Metadata.
- Audit: Set, enforce, and audit standards for Metadata to simplify integration and enable use.
- Improvement | Standards: Create a feedback mechanism so that consumers can inform the Metadata Management team of Metadata that is incorrect or out-of-date.
Metrics
- Metadata repository completeness: Compare ideal coverage of the enterprise oMetadata to actual coverage.
- Metadata Management Maturity:
- Stweard reprensentation
- Metadata usage
- Business Glossary activity
- Master Data service data compliance
- Metadata documentation quality
- Metadata repository availability
Reference & Master Data
- Master Data Management: entails control over Master Data values and identifiers that enable consistent use, across systems, of the most accurate and timely data about essential business entities. The goals of MDM include ensuring availability of accurate, current values while reducing risks associated with ambiguous identifiers (those identified with more than one instance of an entity and those that refer to more than one entity).
- Reference Data Management: entails control over defined domain values and their definition. The goal of RDM is to ensure the organization has access to a complete set of accurate and current values for each concept represented.
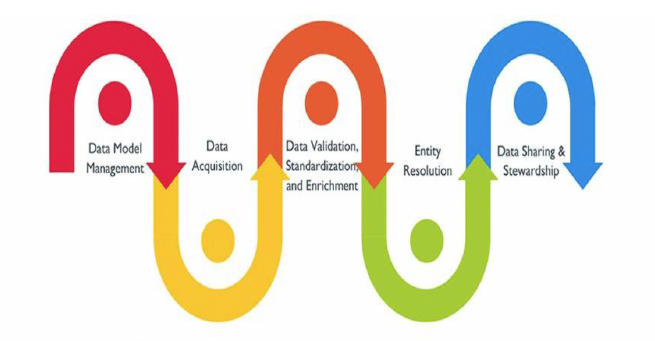
Business Drivers
- meet organizational data requirements
- manage data quality
- manage the costs of data integration
- reduce risk
Principles
- Shared Data
- Ownership
- Quality
- Stewardship
- Controlled Change
- Authority
Data Modelling & Design
Business Drivers
- provide common vocabulary
- capture and document explicit knowledge about an organization’s data and systems
- server as a primary communications tool during projects
- provide the starting point for customization, integraion, or even replacement of an application
Principles
- Formalization: A data model documents a concise definition of data structures and relationships. It enables assessment of how data is affected by implemented business rules, for current as-is states or desired target states. Formal definition imposes a disciplined structure to data that reduces the possibility of data anomalies occurring when accessing and persisting data. By illustrating the structures and relationships in the data, a data model makes data easier to consume.
- Scope Definition: A data model can help explain the boundaries for data context and implementation of purchased application packages, projects, initiatives, or existing systems.
- Knowledge retention/documentation: A data model can preserve corporate memory regarding a system or project by capturing knowledge in an explicit form. It serves as documentation for future projects to use as the as-is version. Data models help us understand an organization or business area, an existing application, or the impact of modifying an existing data structure. The data mode becomes a reusable map to help business professionals, project managers, analysts, modellers, and developers understand data structure within the environment. In much the same way as mapmaker learned and documented a geographic landscape for others to use for navigation, the modeller enables others to understand an information landscape.
1NF (First Normal Form) Rules
- A table is referred to as being in its First Normal Form if atomicity of the table is 1.
- Here, atomicity states that a single cell cannot hold multiple values. It must hold only a single-valued attribute.
- The First normal form disallows the multi-valued attribute, composite attribute, and their combinations.
example:
| roll_no | name | course | age | gender |
|---|---|---|---|---|
| 1 | Rahul | c/c++ | 22 | m |
| 2 | Harsh | java/php | 24 | f |
| 3 | Sahil | python/c++ | 19 | f |
| 4 | Adam | javascript | 40 | m |
In the students record table, you can see that the course column has two values. Thus it does not follow the First Normal Form. Now, if you use the First Normal Form to the above table, you get the below table as a result.
2NF (Second Normal Form) Rules
- The first condition for the table to be in Second Normal Form is that the table has to be in First Normal Form.
- The table should not possess partial dependency.
- The partial dependency here means the proper subset of the candidate key should give a non-prime attribute.
example:
| cust_id | store_id | store_location |
|---|---|---|
| 1 | D1 | Toronto |
| 2 | D3 | Miami |
| 3 | T1 | Florida |
The Location table possesses a composite primary key cust_id, storeid. The non-key attribute is store_location. In this case, store_location only depends on storeid, which is a part of the primary key. Hence, this table does not fulfill the second normal form.
3NF (Third Normal Form) Rules
- The first condition for the table to be in Third Normal Form is that the table should be in the Second Normal Form.
- The second condition is that there should be no transitive dependency for non-prime attributes, which indicates that non-prime attributes (which are not a part of the candidate key) should not depend on other non-prime attributes in a table. Therefore, a transitive dependency is a functional dependency in which A → C (A determines C) indirectly, because of A → B and B → C (where it is not the case that B → A).
- The third Normal Form ensures the reduction of data duplication. It is also used to achieve data integrity.
| stu_id | name | sub_id | sub | address |
|---|---|---|---|---|
| 1 | Arun | 11 | SQL | Delhi |
| 2 | Varun | 12 | Jave | Bangalore |
| 3 | Harsh | 21 | Python | Delhi |
| 4 | Keshav | 21 | Python | Kochi |
In the above student table, stu_id determines subid, and subid determines sub. Therefore, stu_id determines sub via subid. This implies that the table possesses a transitive functional dependency, and it does not fulfill the third normal form criteria.
Boyce CoddNormal Form (BCNF)
- The first condition for the table to be in Boyce Codd Normal Form is that the table should be in the third normal form.
- Secondly, every Right-Hand Side (RHS) attribute of the functional dependencies should depend on the super key of that particular table.
| stu_id | subject | professor |
|---|---|---|
| 1 | Python | Prof. Mishra |
| 2 | C++ | Prof. Anand |
| 3 | JAVA | Prof. Kanth |
| 4 | DBMS | Prof. James |
The subject table follows these conditions:
- Each student can enroll in multiple subjects.
- Multiple professors can teach a particular subject.
- For each subject, it assigns a professor to the student.
In the above table, student_id and subject together form the primary key because using student_id and subject; you can determine all the table columns.
Another important point to be noted here is that one professor teaches only one subject, but one subject may have two professors.
Which exhibit there is a dependency between subject and professor, i.e. subject depends on the professor’s name.
to
The table is in 1st Normal form as all the column names are unique, all values are atomic, and all the values stored in a particular column are of the same domain.
The table also satisfies the 2nd Normal Form, as there is no Partial Dependency.
And, there is no Transitive Dependency; hence, the table also satisfies the 3rd Normal Form.
This table follows all the Normal forms except the Boyce Codd Normal Form.
As you can see stuid, and subject forms the primary key, which means the subject attribute is a prime attribute.
However, there exists yet another dependency - professor → subject.
BCNF does not follow in the table as a subject is a prime attribute, the professor is a non-prime attribute.
To transform the table into the BCNF, you will divide the table into two parts. One table will hold stuid which already exists and the second table will hold a newly created column profid.
| stu_id | pro_id |
|---|---|
| 1 | 3 |
| 2 | 1 |
| 3 | 3 |
| 4 | 5 |
| pro_id | subject | professor |
|---|---|---|
| 1 | Python | Prof. Mishra |
| 2 | C++ | Prof. Anand |
| 3 | JAVA | Prof. Kanth |
| 4 | DBMS | Prof. James |
Data Architecture
Business Drivers
- strategically prepare organizations to quickly evovle their products, services, and data to take advantage of business opportunities inherent in emerging technologies
- translate business needs into data and system requirements so that processes consistently have the data they require
- manage complex data and information delivery throughout the enterprise
- facilitate alignment between business and IT
- act as an agent for change, transformation, and agility
Business Processes
- A process is a set of interrelated actions and activities performed to achieve a pre-specified product, result, or service
- Each process is characterized by its input, the tools and techniques that can be applied, and the resulting outputs
-
Each process can be broken down into other processes, and so on, until we reach a level in which simple activities are defined using measurable inputs and measurable outputs
- Level 0 (“The Context”) shows the relationship between the main process and stakeholders
- Level 1: Level 0 is broken down into major processes
- Level 2: Level 1 is broken down into other processes/activities
- Level n: level n-1 is broken down into measurable tasks
Readiness Assessment/Risk Assessment
- Lack of management support: Any reorganization of the enterprise during the planned execution of the project will affect the architecture process. For example, new decision makers may question the process and be tempted to withdraw from opportunities for participants to continue their work on the Data Architecture. It is by establishing support among management that an architecture process can survive reorganization. Therefore, be certain to enlist into the Data Architecture development process more than one member of top-level management, or at least senior management, who understand the benefits of Data Architecture.
- No proven record of accomplishment: Having a sponsor is essential to the success of the effort, as is his or her confidence in those carrying out the Data Architecture function. Enlist the help of a senior architect colleague to help carry out the most important steps.
- Apprehensive sponsor: If the sponsor requires all communication to pass through them, it may be an indication that that person is uncertain of their role, has interests other than the objectives of the Data Architecture process, or is uncertain of the data architect’s capability. Regardless of the reason, the sponsor must allow the project manager and data architect to take the leading roles in the project. Try to establish independence in the workplace, along with the sponsor’s confidence.
- Counter-productive executive decision: It may be the case that although management understands the value of a well-organized Data Architecture, they do not know how to achieve it. Therefore, they may make decisions that counteract the data architect’s efforts. This is not a sign of disloyal management but rather an indication that the data architect needs to communicate more clearly or frequently with management.
- Culture shock: Consider how the working culture will change among those who will be affected by the Data Architecture. Try to imagine how easy or difficult it will be for the employees to change their behaviour within the organization.
- Inexperienced project leader: Make sure that the project manager has experience with Enterprise Data Architecture particularly if the project has a heavy data component. If this is not the case, encourage the sponsor to change or educate the project manager Dominance of a one-dimensional view: Sometimes the owner of one business application might tend to dictate their view about the overall enterprise-level Data Architecture at the expense of a more well-balanced, all-inclusive view.
Data Integration & Interoperability
DII describes processes related to the movement and consolidation of data within and between data stores, applications and organizations. Integration consolidates data into consistent forms, either physical or virtual. Data interoperability is the ability for multiple systems to communicate.
Business Drivers
- the need to manage data movement efficiently
Goals
- Make data available in the format and timeframe needed by data consumers, both human and system
- Consolidate data physically and virtually into data hubs
- Lower cost and complexity of managing solutions by developing shared models and interfaces
- Identify meaningful events(opportunities and threats) and automatically trigger alerts and actions
- Support Business Intelligence, analytics, Master Data Management, and operational efficiency efforts
Principles
- Take an enterprise perspective in design to ensure future scalability and extensibility
- Balance local data needs with enterprise data needs
- Ensure business accountability
Data Storage & Operations
Data S&O includes the design, implementation and support of stored data, to maximize its value through its lifecycle, from creation/acquisition to disposal
Business Drivers
- business continuity
Goals
- Managing the availability of data throughout the data lifecycle
- Ensuring the integrity of data assets
- Managing the performance of data transactions
Principles
- Identify and act on automation opportunities: automate database development processes, developing tools, and processes that shorten each development cycle, reduce errors and rework, and minimize the impact on the development team. In this way, DBAs can adapt to more iterative approaches to application development. This improvement work should be done in collaboration with data modelling and Data Architecture.
- Build with reuse in mind: Develop and promote the use of abstracted and reusable data objects that prevent applications from being tightly coupled to database schemas. A number of mechanisms exist to this end, including database views, triggers, functions and stored procedures, application data objects and data-access layers, XML and XSLT, ADO.NET typed data sets, and web services. The DBA should be able to assess the best approach virtualizing data. The end goal is to make using the database as quick, easy, and painless as possible
- Understand and appropriately apply best practices: DBAs should promote database standards and best practices as requirements, but be flexible enough to deviate from them if given acceptable reasons for these deviations. Database standards should never be a threat to the success of a project.
- Utilize database standards to support requirements
- Set expectations for the DBA role in project work
A distributed system’s components can be classified depending on the autonomy of the component systems into two types: federated (autonomous) or non-federated (non-autonomous)
Federation provisions data without additional persistence or duplication of source data. A federated database system maps multiple autonomous database systems into a single federated database. The constituent databases, sometimes geographically separated, are interconnected via a computer network. They remain autonomous yet participate in a federation to allow partial and controlled sharing of their data. Federation provides an alternative to merging disparate databases. There is no actual data integration in the constituent database because of data federation; instead, data interoperability manages the view of the federated databases as one large object. In contrast, a non-federated database system is an integration of component DBMS’s that are not autonomous; they aer controlled, managed and governed by a centralized DBMS.
Data Quality
The planning, implementation, and control of activities that apply quality management techniques to data, in order to assure it is fit for consumption and meets the needs of data consumers.
Business Drivers
- increase the value of organizational data and opportunities to use it
- reduce risk and cost associate with poor data quality
- improve organizational efficiency and productivity
- protect and enhance the organization’s reputation
Goals
- Develop a governed approach to meet consumers’ DQ requirements
- Define standards, requirements, specifications, processes, metrics for DQ Monitoring and DQ level control
- Identify, advocate for opportunities to improve data quality
Principles
- Criticality: A DQ program should focus on the data most critical to the enterprise and its customers. Priorities for improvement should be based on the criticality of the data and on the level of risk if data is not correct
- Lifecycle Management: The quality of data should be managed across the data lifecycle, from creation or procurement through disposal. This includes managing data as it moves within and between systems.
- Prevention: This focus of a DQ program should be on preventing data errors and conditions that reduce the usability of data; it should not be focus on simply correcting records.
- Root cause remediation: Improving the quality of data goes beyond correcting errors. Problems with the quality of data should be understood and addressed at their root causes, rather than just their symptoms. Because these causes are often related to process or system design, improving data quality often requires changes to processes and the systems that support them.
- Governance: Data Governance activities must support the development of high quality data and DQ program activities must support and sustain a governed data environment.
- Standards-driven: All stakeholders in the data lifecycle have data quality requirements. To the degree possible, these requirements should be defined in the form of measurable standards and expectations against which the quality of data can be measured.
- Objective measurement and transparency: Data quality levels need to be measured objectively and consistently. Measurements and measurement methodology should be shared with stakeholders since they are the arbiters of quality.
- Embedded in business processes: Business process owners are responsible for the quality of data produced through their process. They must enforce data quality standards in their processes.
- Connected to service levels: Data quality reporting and issues management should be incorporated into SLA.
- Systematically enforced: System owners must systematically enforce data quality requirements.
Policy
- Purpose, scope and applicability of the policy
- Definitions of terms
- Responsibilities of the Data Quality program
- Responsibilities of other stakeholders
- Reporting
- Implementation of the policy, including links to risk, preventative measures, compliance, data protection, and data security
Data Security
Definition, planning, development, and execution of security policies and procedures to provide proper authentication, authorization access, and auditing of data and information assets
Business Drivers
- risk reduction
- business growth
- security as an asset
Goals
- Enabling appropriate, and preventing inappropriate access to data assets
- Enabling compliance with regulations, policies for privacy, protection, and confidentiality
- Ensuring that stakeholder requirements for privacy and confidentiality are met
Principles
- Collaboration: Data Security is a collaborative effort involving IT security administrators, data stewards/data governance, internal and external audit teams, and the legal department.
- Enterprise approach: Data Security standards and policies must be applied consistently across the entire organization.
- Proactive management: Success in data security management depends on being proactive and dynamic, engaging all stakeholders, managing change, and overcoming organizational or cultural bottlenecks such as traditional separation of responsibilities between information security, information technology, data administration, and business stakeholders.
- Clear accountability: Roles and responsibilities must be clearly defined, including the ‘chain of custody’ for data across organizations and roles.
- Metadata-driven: Security classification for data elements is an essential part of data definitions.
- Reduce risk by reducing exposure: Minimize sensitive/confidential data proliferation, especially to non-production environments.
Security Processes
4 A’s
- Access
- Audit
- Authentication
- Authorization
- entitlement
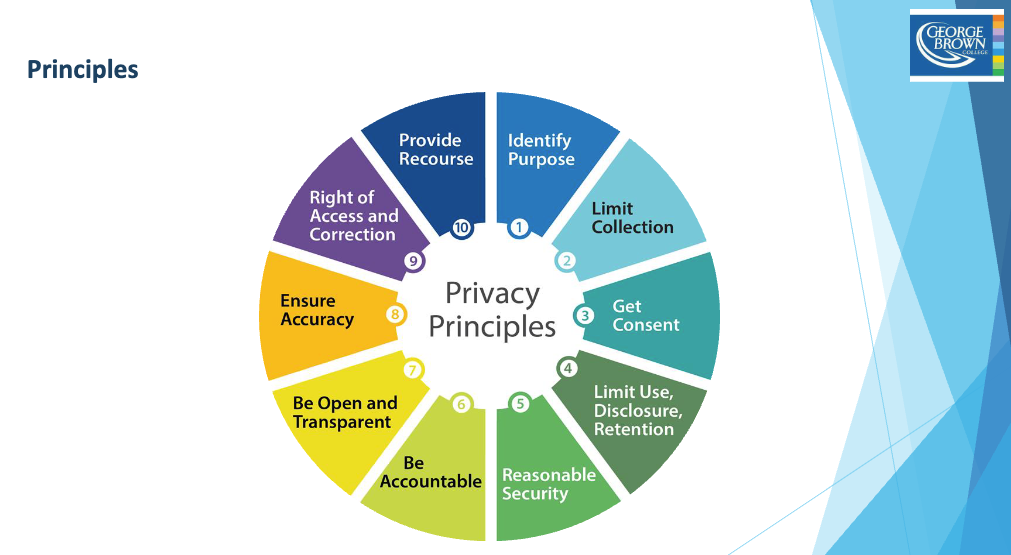
Data Privacy
The exercise of monitoring, and enforcement, and shared decision-making over privacy of Data
Goals
- Identify sensitive data
- Flag sensitive data within the metadata repository
- Address privacy laws and restrictions by country, state or province
- Manage situation where personal data crosses international boundaries
- Monitor access to sensitive data by privileged users
Principles
- Be Accountable. Be responsible, by contractual or other means, for all personal information under your control.
- Identify the Purpose
- Obtain Consent
- Limit Collection
- Limit Use, Disclosure and Retention
- Be Accurate
- Use Appropriate Safeguards
- Be Open
- Give Individuals Access
- Provide Recourse
Document & Content Management
Planning, implementation, and control activities for lifecycle management of data and information found in any form or medium.
Document and Content Management entails controlling the capture, storage, access, and use of data and information stored outside relational databases.
Its focus is on maintaining the quality, security, integrity of and enabling access to documents and other unstructured information.
Business Drivers
- regulatory compliance
- ability to respond to litigation and e-discovery
Goals
- Comply with legal obligations, and customer expectations regarding Records management
- Ensure effective, efficient storage, retrieval, use of documents and content
- Ensure integration capabilities between structured, unstructured content
Principles
- Everyone must create, use, retrieve, and dispose of records in accordance with the established policies and procedures
- Experts in handling of Records and Content should be fully engaged in policy and planning, and should comply with regulations and best practices
E-discovery is the process of finding electronic records that might serve as evidence in a legal action. As the technology for creating, storing, and using data has developed, the volume of ESI has increased exponentially. Some of this data will undoubtedly end up in litigation or regulatory requests.
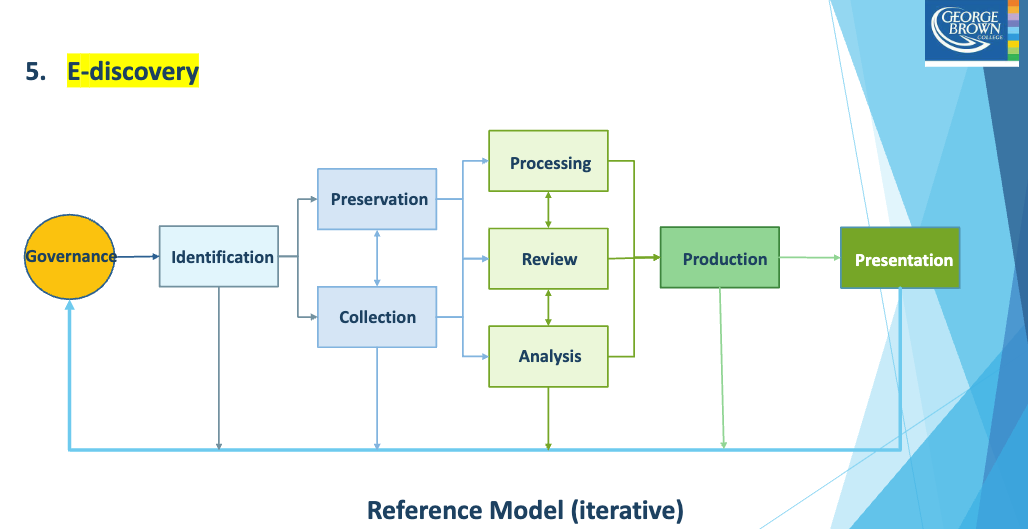
Volume -> Relevance
As e-discovery progresses, the volume of discoverable data and information is greatly reduced as their relevance is greatly increased.